ELT Pipeline with Medallion Architecture
Value statement: Production ELT pipeline implementing medallion architecture with dbt transformations, Kimball dimensional modeling, and 99%+ data quality through automated testing.
Overview
Built a production-grade ELT pipeline using medallion architecture (Bronze/Silver/Gold) with dbt transformations orchestrated by Apache Airflow. The pipeline features dimensional models with star schema design, comprehensive dbt testing, and incremental processing that reduces run times from 45 minutes to 8 minutes.
Architecture
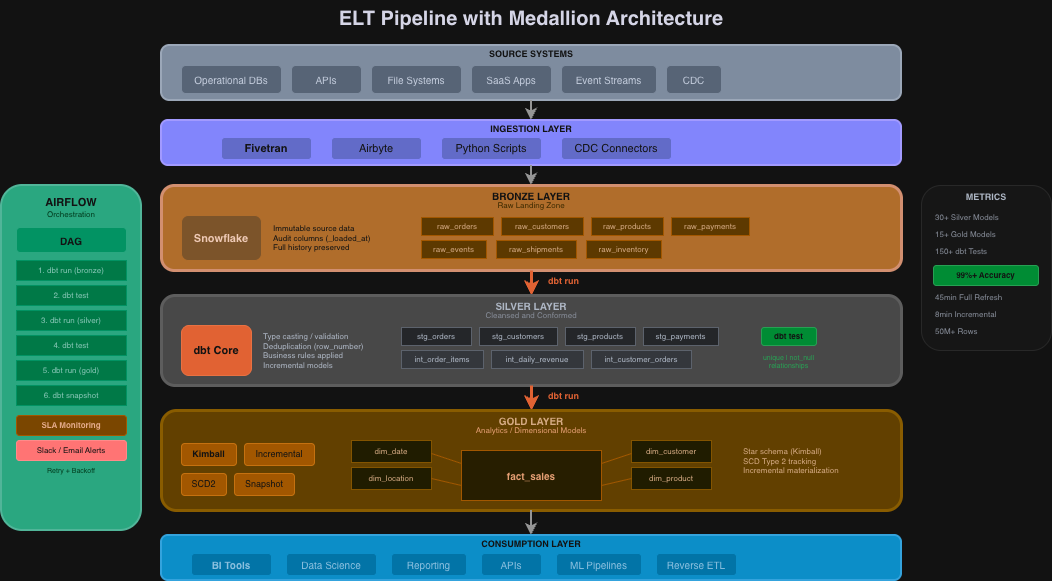
Technology Stack
| Layer | Technologies |
|---|---|
| Transformation | dbt Core, Jinja, SQL |
| Data Warehouse | Snowflake |
| Orchestration | Apache Airflow |
| Testing | dbt tests (schema + data quality) |
| Modeling | Kimball dimensional modeling |
Implementation Details
Medallion Layers
Bronze (Raw): Immutable source data with _loaded_at and _source_system audit columns. Preserves full history for reprocessing.
Silver (Cleansed): Type casting, deduplication via row_number(), and business rule validation. Uses incremental models with merge strategy.
Gold (Analytics): Fact tables (fact_sales, fact_orders) and dimensions (dim_customer, dim_product, dim_date) following Kimball methodology. SCD Type 2 preserves historical changes.
Data Quality Testing
Comprehensive dbt test suite achieving 99%+ accuracy:
- Schema tests: Uniqueness, not-null, relationships, accepted values
- Custom tests: Business logic validation (e.g.,
order_date < ship_date) - Freshness tests: SLA monitoring for data staleness
Orchestration
Airflow DAG coordinates the pipeline:
- Sequence:
dbt run→dbt test→dbt snapshot - SLA monitoring with Slack/email alerts on breaches
- Retry logic with exponential backoff
- Test failures halt downstream tasks
Metrics
| Metric | Value |
|---|---|
| Silver Models | 30+ staging models |
| Gold Models | 15+ fact/dimension tables |
| dbt Tests | 150+ automated tests |
| Accuracy | 99%+ |
| Full Refresh | 45 minutes |
| Incremental | 8 minutes |
| Data Volume | 50M+ rows |
Reliability
- Schema evolution:
on_schema_change='append_new_columns'handles additive changes - Late-arriving data: SCD Type 2 updates dimensions retroactively
- Idempotency: Unique key constraints prevent duplicates on re-runs
- Backfill: Date-range macros enable historical reprocessing
Lessons Learned
Incremental strategy: Switched from unique_key to partitioned merge with date filtering, reducing processing time 70%.
Test early: Moved custom business logic tests to Silver layer to catch issues before Gold.
Star schema simplicity: Removed snowflaking from dimensions, improving BI query performance 3x.
Future Improvements
- Great Expectations for statistical data quality
- dbt metrics layer for semantic consistency
- Data contracts with schema enforcement at ingestion
- Row-level security for multi-tenant access