Why I Use dbt with BigQuery (And You Should Too)
How dbt transforms BigQuery development with version-controlled models, incremental builds, and automated documentation for analytics engineering.
· projects · 1 minutes
Why I Use dbt with BigQuery (And You Should Too)
If you’re writing SQL transformations in BigQuery, whether through scheduled queries, stored procedures, or Airflow operators, dbt can make your life significantly better. Here’s why.
SQL Gets Version Control
dbt projects are just SQL files in a Git repository. Every model, test, and macro is tracked, reviewed, and deployed through standard CI/CD. Compare this to scheduled queries managed through the BigQuery console — no history, no review process, no rollback.
Built-In Testing and Documentation
dbt lets you declare tests inline: unique, not_null, accepted_values, and relationships tests catch data quality issues before they propagate downstream. Documentation is generated automatically from schema YAML files and rendered as a searchable website.
models: - name: dim_customers description: "One row per customer with latest attributes" columns: - name: customer_id tests: - unique - not_null - name: segment tests: - accepted_values: values: ['enterprise', 'mid_market', 'smb']Incremental Models Save Money
Instead of rebuilding a table from scratch every run, incremental models process only new or changed records:
{{ config( materialized='incremental', partition_by={'field': 'event_date', 'data_type': 'date'}, incremental_strategy='merge', unique_key='event_id') }}
SELECT *FROM {{ source('raw', 'events') }}{% if is_incremental() %}WHERE event_date >= (SELECT MAX(event_date) FROM {{ this }}){% endif %}On BigQuery specifically, this means you scan less data and pay less.
The Dependency Graph
dbt builds a DAG of your models automatically via {{ ref('model_name') }}. This means transformations run in the correct order, and you can visualize your entire data lineage. When something breaks, you know exactly what’s upstream and downstream.
Takeaway: dbt brings software engineering practices — version control, testing, documentation, modularity — to SQL transformations. If BigQuery is your warehouse, dbt is the natural companion.
More posts
-
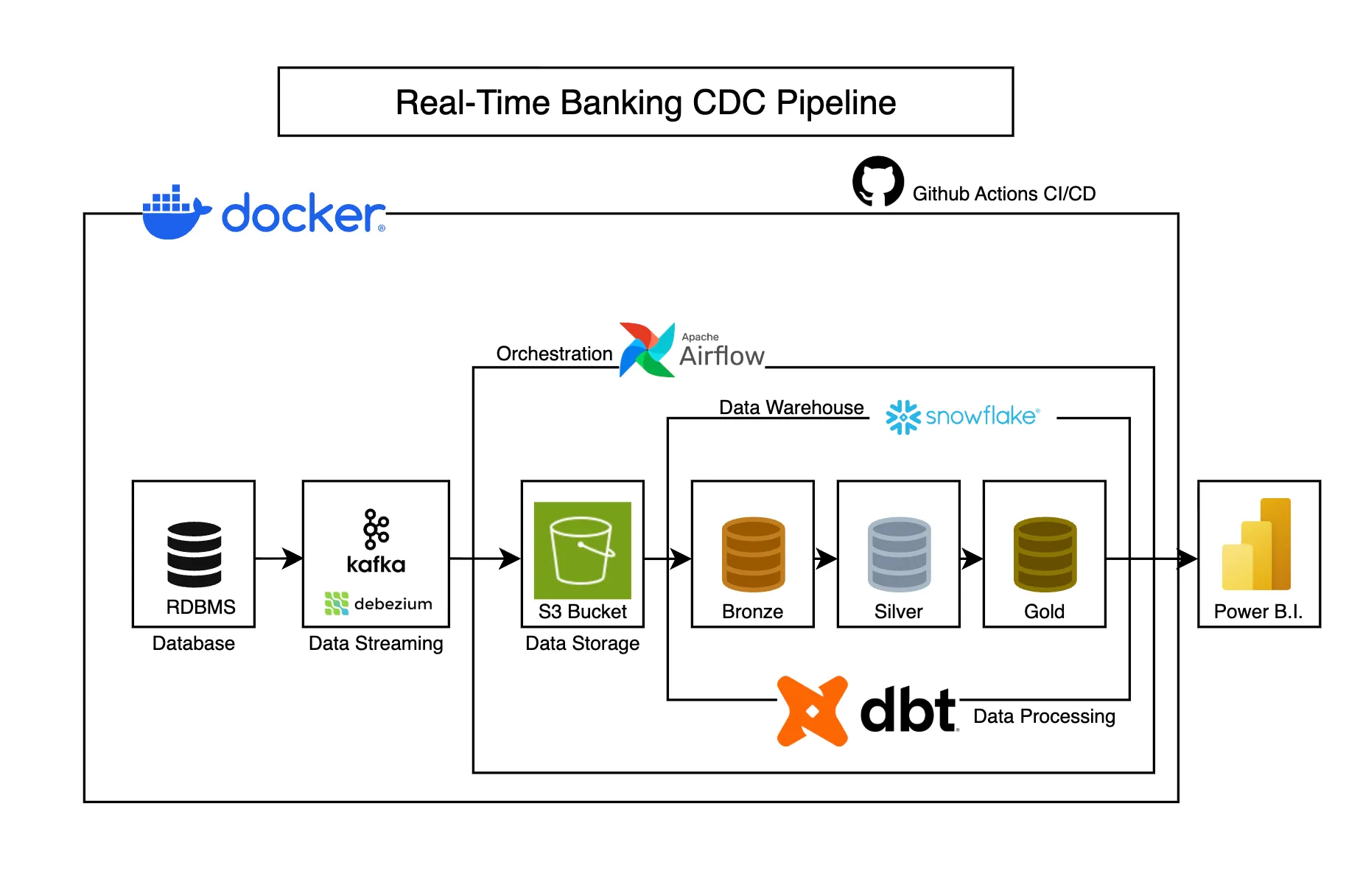
Real-Time Banking CDC Pipeline
Captures banking transaction changes in real-time using CDC, transforming operational data into analytics-ready models for business intelligence.
-
Docker for Data Engineers — Containerizing Python Pipelines
Build reproducible data pipelines with Docker. Covers multi-stage builds, dependency management, and patterns for PySpark and Airflow containers.
-
BigQuery Cost Optimization - 5 Patterns Every Data Engineer Should Know
Reduce BigQuery costs with partitioning, clustering, materialized views, and query optimization techniques that actually work in production.